介绍
 人工智能就是使用机器来提升人们的生活和生活方式,让他们的平凡生活变得有趣和简单。 人工智能永远不应该是一种主导力量,而是一种互补的力量,它与人类协同工作以解决难以置信的问题并为集体进化铺平道路。
人工智能就是使用机器来提升人们的生活和生活方式,让他们的平凡生活变得有趣和简单。 人工智能永远不应该是一种主导力量,而是一种互补的力量,它与人类协同工作以解决难以置信的问题并为集体进化铺平道路。
截至目前,我们正走在正确的道路上,在人工智能的帮助下,各个行业都取得了重大突破。 以医疗保健为例,带有机器学习模型的人工智能系统正在帮助专家更好地了解癌症并提出治疗方法。 神经系统疾病和创伤后应激障碍等问题正在人工智能的帮助下得到治疗。 由于人工智能驱动的临床试验和模拟,疫苗正在快速开发中。
不仅仅是医疗保健,人工智能涉及的每个行业或细分领域都在发生革命性的变化。 自动驾驶汽车、智能便利店、FitBit 等可穿戴设备,甚至我们的智能手机摄像头都能够通过 AI 捕捉到更好的面部图像。
由于人工智能领域的创新,公司正在通过各种用例和解决方案闯入这个领域。 因此,到 267 年底,全球人工智能市场的市值预计将达到约 2027 亿美元。此外,大约 37% 的企业已经在其流程和产品中实施人工智能解决方案。
更有趣的是,我们今天使用的产品和服务中有近 77% 是由人工智能提供支持的。 随着技术概念在垂直领域显着上升,企业如何利用人工智能做到不可能?

 像手表这样简单的设备如何准确预测人类的心脏病发作? 一直需要司机的汽车和汽车怎么可能突然在道路上减少司机?
像手表这样简单的设备如何准确预测人类的心脏病发作? 一直需要司机的汽车和汽车怎么可能突然在道路上减少司机?
聊天机器人如何让我们相信我们正在与另一边的另一个人交谈?
如果你观察每一个问题的答案,它就会归结为一个元素——数据。 数据是所有特定于 AI 的操作和流程的中心。 它是帮助机器理解概念、处理输入并提供准确结果的数据。
现有的所有主要 AI 解决方案都是我们称为数据收集或数据采集或 AI 训练数据的关键过程的所有产品。
这份详尽的指南旨在帮助您了解它是什么以及它为何重要。
什么是人工智能数据采集?
机器没有自己的头脑。 缺乏这个抽象概念使他们缺乏意见、事实和推理、认知等能力。 它们只是占据空间的不可移动的盒子或设备。 要将它们变成强大的媒介,您需要算法,更重要的是数据。
 开发的算法需要一些东西来处理和处理,这些东西是相关的、上下文的和最新的数据。 为机器收集此类数据以达到其预期目的的过程称为人工智能数据收集。
开发的算法需要一些东西来处理和处理,这些东西是相关的、上下文的和最新的数据。 为机器收集此类数据以达到其预期目的的过程称为人工智能数据收集。
我们今天使用的每一个支持 AI 的产品或解决方案及其提供的结果都源于多年的培训、开发和优化。 从提供导航路线的设备到提前几天预测设备故障的复杂系统,每个实体都经历了多年的人工智能培训,才能准确交付结果。
人工智能数据采集 是人工智能开发过程中的第一步,从一开始就决定了人工智能系统的有效性和效率。 这是从无数来源获取相关数据集的过程,这将有助于 AI 模型更好地处理细节并产生有意义的结果。




如何为机器学习收集数据?
 这就是事情开始变得有点棘手的地方。 从一开始,您似乎已经想到了解决现实世界问题的方法,您知道 AI 将是解决此问题的理想方式,并且您已经开发了模型。 但是现在,您正处于需要开始 AI 培训过程的关键阶段。 你需要丰富的人工智能训练数据,让你的模型学习概念并交付结果。 您还需要验证数据来测试您的结果并优化您的算法。
这就是事情开始变得有点棘手的地方。 从一开始,您似乎已经想到了解决现实世界问题的方法,您知道 AI 将是解决此问题的理想方式,并且您已经开发了模型。 但是现在,您正处于需要开始 AI 培训过程的关键阶段。 你需要丰富的人工智能训练数据,让你的模型学习概念并交付结果。 您还需要验证数据来测试您的结果并优化您的算法。
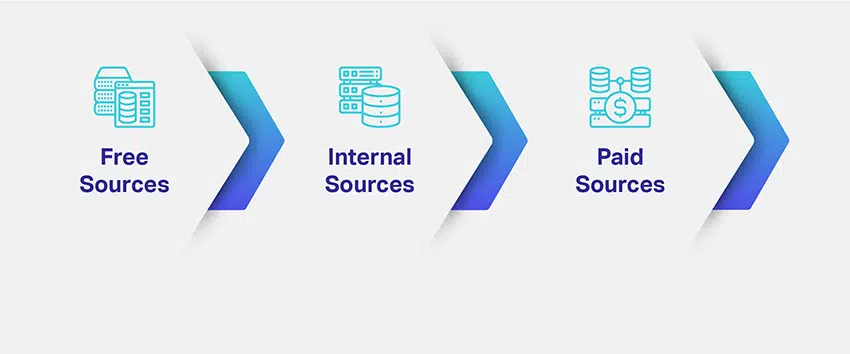
那么,您如何获取数据? 您需要哪些数据以及需要多少数据? 获取相关数据的多个来源是什么?
公司评估其 ML 模型的利基和目的,并绘制出获取相关数据集的潜在方法。 定义所需的数据类型可以解决您对数据来源的主要担忧。 为了让您有更好的想法,数据收集有不同的渠道、途径、来源或媒介:
不良数据如何影响您的 AI 抱负?
我们列出了三种最常见的数据资源,因为您将了解如何进行数据收集和采购。 然而,在这一点上,了解您的决定总是会决定您的 AI 解决方案的命运变得至关重要。
与高质量的 AI 训练数据如何帮助您的模型提供准确及时的结果类似,糟糕的训练数据也会破坏您的 AI 模型、扭曲结果、引入偏差并产生其他不良后果。
但为什么会发生这种情况? 不应该有任何数据来训练和优化您的 AI 模型吗? 老实说,没有。 让我们进一步了解这一点。
坏数据——是什么?
 不良数据是任何不相关、不正确、不完整或有偏见的数据。 由于定义不明确的数据收集策略,大多数数据科学家和 注释专家 被迫处理不良数据。
不良数据是任何不相关、不正确、不完整或有偏见的数据。 由于定义不明确的数据收集策略,大多数数据科学家和 注释专家 被迫处理不良数据。
非结构化数据和不良数据之间的区别在于,对非结构化数据的洞察无处不在。 但本质上,它们无论如何都可能有用。 通过花费更多时间,数据科学家仍然能够从非结构化数据集中提取相关信息。 但是,对于不良数据,情况并非如此。 这些数据集不包含/有限的见解或信息,这些见解或信息对您的 AI 项目或其培训目的有价值或相关。
因此,当您从免费资源中获取数据集或建立松散的内部数据接触点时,您很有可能会下载或生成不良数据。 当您的科学家处理不良数据时,您不仅在浪费人力,而且还在推动产品的发布。
如果您仍然不清楚不良数据会对您的抱负造成什么影响,这里有一个快速列表:
- 您花费无数时间寻找不良数据,并在资源上浪费时间、精力和金钱。
- 如果不被注意,错误数据可能会给您带来法律问题,并可能降低您的 AI 的效率
楷模。 - 当您将接受不良数据训练的产品上线时,它会影响用户体验
- 糟糕的数据可能会使结果和推论产生偏差,这可能会进一步引起强烈反对。
所以,如果你想知道是否有解决方案,实际上是有的。
AI 训练数据提供者来救援
 基本的解决方案之一是寻找数据供应商(付费来源)。 AI 培训数据提供商可确保您收到的内容准确且相关,并且您以结构化的形式向您提供数据集。 您不必参与从门户移动到门户以搜索数据集的麻烦。
基本的解决方案之一是寻找数据供应商(付费来源)。 AI 培训数据提供商可确保您收到的内容准确且相关,并且您以结构化的形式向您提供数据集。 您不必参与从门户移动到门户以搜索数据集的麻烦。
您所要做的就是接收数据并训练您的 AI 模型以求完美。 话虽如此,我们确信您的下一个问题是与数据供应商合作所涉及的费用。 我们知道你们中的一些人已经在制定心理预算,而这正是我们接下来要走的方向。
为您的数据收集项目制定有效预算时要考虑的因素
AI 培训是一种系统方法,这就是为什么预算成为其中不可或缺的一部分。 在将大量资金投入 AI 开发之前,应考虑投资回报率、结果准确性、培训方法等因素。 许多项目经理或企业主在这个阶段摸索。 他们做出草率的决定,给他们的产品开发过程带来不可逆转的变化,最终迫使他们花费更多。
但是,本节将为您提供正确的见解。 当你坐下来处理 AI 培训的预算时,三件事或因素是不可避免的。

让我们详细看看每一个。
您需要的数据量
我们一直在说,你的 AI 模型的效率和准确性取决于它的训练程度。 这意味着数据集的数量越多,学习就越多。 但这是非常模糊的。 Dimensional Research 发布的一份报告显示,企业至少需要 100,000 个样本数据集来训练他们的 AI 模型。
通过 100,000 个数据集,我们的意思是 100,000 个质量和相关的数据集。 这些数据集应该具有算法和机器学习模型处理信息和执行预期任务所需的所有基本属性、注释和见解。
这是一般的经验法则,让我们进一步了解您需要的数据量还取决于另一个复杂的因素,即您的业务用例。 您打算对您的产品或解决方案做什么也决定了您需要多少数据。 例如,构建推荐引擎的企业与构建聊天机器人的公司具有不同的数据量要求。
数据定价策略
当您最终确定实际需要多少数据后,接下来需要制定数据定价策略。 简单来说,这意味着您将如何为采购或生成的数据集付费。
一般来说,这些是市场上遵循的常规定价策略:
| 数据类型 | 定价策略 |
|---|---|
| 按单个图像文件定价 | |
| 按秒、分钟、一小时或单个帧定价 | |
| 按秒、分钟或小时定价 | |
| 按单词或句子定价 |
可是等等。 这又是一个经验法则。 采购数据集的实际成本还取决于以下因素:
- 必须从哪里获取数据集的独特细分市场、人口统计数据或地理位置
- 用例的复杂性
- 你需要多少数据?
- 您的上市时间
- 任何量身定制的要求等等
如果您观察一下,您就会知道为您的 AI 项目获取大量图像的成本可能会更低,但如果您的规格太多,价格可能会飙升。
您的采购策略
这很棘手。 正如您所见,有多种方法可以为您的 AI 模型生成或获取数据。 常识表明免费资源是最好的,因为您可以免费下载所需数量的数据集而不会出现任何复杂情况。
现在,付费来源似乎也太贵了。 但这就是增加了一层复杂性的地方。 当您从免费资源中获取数据集时,您需要花费额外的时间和精力来清理数据集、将它们编译为特定于业务的格式,然后对它们进行单独注释。 在此过程中,您会产生运营成本。
使用付费来源,付款是一次性的,您还可以在需要的时候获得机器就绪的数据集。 这里的成本效益是非常主观的。 如果您觉得自己有能力花时间对免费数据集进行注释,则可以相应地进行预算。 如果您认为您的竞争激烈且上市时间有限,您可以在市场上产生连锁反应,那么您应该更喜欢付费资源。
预算就是分解细节并明确定义每个片段。 这三个因素应该可以作为您未来 AI 培训预算过程的路线图。
您是否通过内部数据采集节省了开支?
 在制定预算时,我们探索了免费资源如何迫使您从长远来看花费更多。 那时,您会不自觉地想知道内部数据采集过程的成本效益。
在制定预算时,我们探索了免费资源如何迫使您从长远来看花费更多。 那时,您会不自觉地想知道内部数据采集过程的成本效益。
我们知道您仍然对付费来源犹豫不决,这就是为什么本节将消除您对此的怀疑并阐明内部数据生成所涉及的隐藏成本。
内部数据采集是否昂贵?
是的!
现在,这是一个精心设计的回应。 费用是您花费的任何东西。 在讨论免费资源时,我们透露您在此过程中花费了金钱、时间和精力。 这也适用于内部数据采集。
 由于您拥有自定义的接触点或数据漏斗,这并不意味着您将拥有 机器就绪数据集 到底。 您生成的数据仍然主要是原始的和非结构化的。 您可能在一个地方拥有所需的所有数据,但数据包含的内容将无处不在。
由于您拥有自定义的接触点或数据漏斗,这并不意味着您将拥有 机器就绪数据集 到底。 您生成的数据仍然主要是原始的和非结构化的。 您可能在一个地方拥有所需的所有数据,但数据包含的内容将无处不在。
最终,您最终将花费在支付员工、数据科学家、注释员、质量保证专业人员等方面。 您还将在订阅注释工具和
CMS、CRM 和其他基础设施的维护费用。
此外,数据集必然存在偏差和准确性问题,您需要手动对它们进行排序。 如果您的 AI 培训数据团队存在人员流失问题,您将不得不花钱招募新成员,让他们适应您的流程,培训他们使用您的工具等等。
从长远来看,您最终会花费更多。 还有注释费用。 在任何给定时间点,使用内部数据产生的总成本为:
产生的成本 = 注释者数量 * 每个注释者的成本 + 平台成本
如果您的 AI 培训日程安排为数月,请想象一下您将持续产生的费用。 那么,这是解决数据采集问题的理想解决方案还是有其他选择?
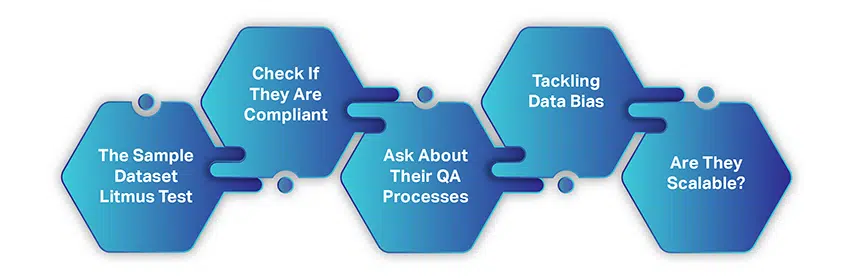
如何选择合适的人工智能数据采集公司
选择 AI 数据收集公司并不像从免费资源中收集数据那么复杂或耗时。 您只需要考虑几个简单的因素,然后就可以握手进行合作。
当您开始寻找数据供应商时,我们假设您已经遵循并考虑了我们迄今为止讨论的任何内容。 但是,这里有一个快速回顾:
- 您有一个明确定义的用例
- 您的细分市场和数据要求已经明确
- 您的预算很到位
- 并且您了解所需的数据量
勾选这些项目后,让我们了解如何寻找理想的训练数据服务提供商。