
自动语音识别系统和 Siri、Alexa 和 Cortana 等虚拟助手已成为我们生活中常见的一部分。 随着它们变得越来越聪明,我们对它们的依赖显着增加。 从开灯到打电话到更换电视频道,我们利用这些智能技术来完成日常任务。
但是,您有没有想过这些语音识别系统是如何工作的?
好吧,这个博客将向您介绍自动语音识别的一些基础知识。 此外,我们将探索它的工作原理以及如何构建像 Siri 这样的功能性虚拟助手。
什么是自动语音识别?
自动语音识别 (ASR) 是一种软件,它使计算机系统能够利用多种人工智能和机器学习算法将人类语音转换为文本。
在转换和分析给定命令后,计算机会为用户提供适当的输出响应。 ASR 于 1962 年首次推出,从那时起,由于 Alexa 和 Siri 等流行应用程序,它一直在不断改进其操作并获得巨大的关注。
您知道自动语音识别也称为语音转文本阅读器吗? 在此博客中阅读有关它的更多信息!
训练 ASR 模型的语音收集过程是什么?
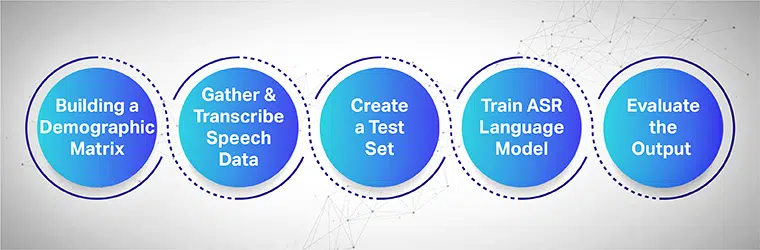
语音收集旨在从多个区域收集多个样本录音,用于提供和训练 ASR 模型。 当收集大型语音和音频数据集并将其提供给其系统时,ASR 系统可提供最高效率。
为了无缝工作,收集的语音数据集必须包含所有目标人口统计、语言、口音和方言。 以下过程展示了如何通过多个步骤训练机器学习模型:
从建立人口矩阵开始
最重要的是收集不同人口统计的数据,例如位置、性别、语言、年龄和口音。 此外,确保捕获各种环境噪音,如街道噪音、候诊室噪音、公共办公室噪音等。
收集和转录语音数据
下一步是根据不同的地理位置收集人类音频和语音样本,以训练您的 ASR 模型。 这是一个重要的步骤,需要人类专家执行长短的单词发音以获得句子的真实感觉,并以不同的口音和方言重复相同的句子。
创建单独的测试集
收集转录文本后,下一步是将其与相应的音频数据配对。 然后,进一步分割数据并包含其中的一条语句。 现在,从分段数据对中,您可以从集合中提取随机数据以进行进一步测试。
训练您的 ASR 语言模型
您的数据集拥有的信息越多,您的 AI 训练模型的性能就越好。 因此,生成您之前录制的文本和语音的多种变体。 使用不同的语音符号来解释相同的句子。
评估输出,最后迭代
最后,测量 ASR 模型的输出以修复其性能。 针对测试集测试模型以确定其效率。 适当地,让您的 ASR 模型参与反馈循环,以生成所需的输出并修复任何差距。
[另请阅读: 自动语音识别的全面概述]

语音识别有哪些不同的用例?
语音识别技术在当今许多行业中非常流行。 一些使用这种巨大技术的行业如下:
 食品工业: Wendy's 和 McDonald's 等食品巨头将使用 ASR 来增强他们的客户体验。 在他们的许多门店中,他们部署了功能齐全的 ASR 模型来接受订单,并进一步将它们传递到烹饪区,以便为客户准备好订单。
食品工业: Wendy's 和 McDonald's 等食品巨头将使用 ASR 来增强他们的客户体验。 在他们的许多门店中,他们部署了功能齐全的 ASR 模型来接受订单,并进一步将它们传递到烹饪区,以便为客户准备好订单。- 电信: 沃达丰是世界上最大的电信供应商之一。 它利用 ASR 模型设计了客户服务和电话中继服务,指导您解决不同的查询并将您的电话重新路由到相关部门。
- 旅行和交通: 谷歌 Android Auto 或 Apple CarPlay 已经变得很普遍。 大多数人使用它们来激活导航系统、发送消息或切换音乐播放列表。 然而,随着技术的进步,这样的系统正变得越来越精细。
BMW 3系推出的BMW智能个人助理比普通语音助手要智能得多。 它可以使驾驶员找到汽车相关信息并使用语音命令操作汽车。 - 媒体和娱乐: 媒体行业也在其许多项目中使用 ASR。 Youtube 推出了一个基于人工智能的助手,可以生成实时自动字幕。 当您在屏幕上讲话时,助手将提供字幕,以使更多 Youtube 用户可以访问视频。
 食品工业: Wendy's 和 McDonald's 等食品巨头将使用 ASR 来增强他们的客户体验。 在他们的许多门店中,他们部署了功能齐全的 ASR 模型来接受订单,并进一步将它们传递到烹饪区,以便为客户准备好订单。
食品工业: Wendy's 和 McDonald's 等食品巨头将使用 ASR 来增强他们的客户体验。 在他们的许多门店中,他们部署了功能齐全的 ASR 模型来接受订单,并进一步将它们传递到烹饪区,以便为客户准备好订单。 电信: 沃达丰是世界上最大的电信供应商之一。 它利用 ASR 模型设计了客户服务和电话中继服务,指导您解决不同的查询并将您的电话重新路由到相关部门。
电信: 沃达丰是世界上最大的电信供应商之一。 它利用 ASR 模型设计了客户服务和电话中继服务,指导您解决不同的查询并将您的电话重新路由到相关部门。 旅行和交通: 谷歌 Android Auto 或 Apple CarPlay 已经变得很普遍。 大多数人使用它们来激活导航系统、发送消息或切换音乐播放列表。 然而,随着技术的进步,这样的系统正变得越来越精细。
旅行和交通: 谷歌 Android Auto 或 Apple CarPlay 已经变得很普遍。 大多数人使用它们来激活导航系统、发送消息或切换音乐播放列表。 然而,随着技术的进步,这样的系统正变得越来越精细。 媒体和娱乐: 媒体行业也在其许多项目中使用 ASR。 Youtube 推出了一个基于人工智能的助手,可以生成实时自动字幕。 当您在屏幕上讲话时,助手将提供字幕,以使更多 Youtube 用户可以访问视频。
媒体和娱乐: 媒体行业也在其许多项目中使用 ASR。 Youtube 推出了一个基于人工智能的助手,可以生成实时自动字幕。 当您在屏幕上讲话时,助手将提供字幕,以使更多 Youtube 用户可以访问视频。
[另请阅读: 什么是语音转文本技术及其工作原理]
夏普如何提供帮助?
Shaip 是领先的 AI 培训服务公司之一,在 AI 和 ML 的多个领域拥有专业知识。 它们可以帮助您构建自己的数据集,可用于不同的应用程序和项目。
Shaip 提供的一些服务包括:
- 自动语音识别 (ASR)
- 脚本语音集合
- 创译
- 自发语音采集
- 话语收集/唤醒词,
- 文字转语音 (TTS)
您可以利用这些服务为基于人工智能的项目获得最佳结果。 立即联系我们的专家团队,了解有关这些服务的更多信息!


