
人工智能和大数据有可能找到全球问题的解决方案,同时优先考虑当地问题并以许多深刻的方式改变世界。 AI 为所有人带来解决方案——在所有环境中,从家庭到工作场所。 人工智能计算机,与 机器学习 培训,可以以自动化但个性化的方式模拟智能行为和对话。
然而,人工智能面临着包容性问题,而且往往存在偏见。 幸运的是,专注于 人工智能伦理 通过多样化的训练数据消除无意识的偏见,可以在多元化和包容性方面带来新的可能性。
人工智能训练数据多样性的重要性
 训练数据的多样性和质量是相关的,因为两者相互影响并影响 AI 解决方案的结果。 人工智能解决方案的成功取决于 多样化的数据 它受过训练。 数据多样性可防止 AI 过度拟合——这意味着模型仅执行或从用于训练的数据中学习。 由于过度拟合,AI 模型无法在对训练中未使用的数据进行测试时提供结果。
训练数据的多样性和质量是相关的,因为两者相互影响并影响 AI 解决方案的结果。 人工智能解决方案的成功取决于 多样化的数据 它受过训练。 数据多样性可防止 AI 过度拟合——这意味着模型仅执行或从用于训练的数据中学习。 由于过度拟合,AI 模型无法在对训练中未使用的数据进行测试时提供结果。
人工智能培训的现状 data
数据中的不平等或缺乏多样性会导致不公平、不道德和非包容性的人工智能解决方案,从而加深歧视。 但是,数据多样性如何以及为何与 AI 解决方案相关?
所有类别的不平等代表会导致面部识别错误——一个重要的例子是谷歌照片,它将一对黑人夫妇归类为“大猩猩”。 Meta 会提示正在观看黑人视频的用户是否愿意“继续观看灵长类动物的视频”。
例如,对少数民族的分类不准确或不当,尤其是在聊天机器人中,可能会导致人工智能训练系统出现偏见。 根据2019年的报告 歧视系统——人工智能中的性别、种族、权力, 超过 80% 的 AI 教师是男性; FB 上的女性 AI 研究人员仅占谷歌的 15% 和 10%。
多样化训练数据对 AI 性能的影响
 从数据表示中遗漏特定的群体和社区可能会导致算法出现偏差。
从数据表示中遗漏特定的群体和社区可能会导致算法出现偏差。
数据偏差经常被意外地引入数据系统——通过对某些种族或群体的抽样不足。 当面部识别系统在不同的面孔上进行训练时,它可以帮助模型识别特定特征,例如面部器官的位置和颜色变化。
标签频率不平衡的另一个结果是,系统可能会在加压以在短时间内产生输出时将少数视为异常。
实现人工智能训练数据的多样性
另一方面,生成多样化的数据集也是一个挑战。 某些类别的数据完全缺乏可能导致代表性不足。 它可以通过让人工智能开发团队在技能、种族、种族、性别、纪律等方面更加多样化来缓解。 此外,解决人工智能中数据多样性问题的理想方法是从一开始就面对它,而不是试图修复已经完成的事情——在数据收集和管理阶段注入多样性。
不管围绕人工智能的炒作如何,它仍然取决于人类收集、选择和训练的数据。 人类天生的偏见会反映在他们收集的数据中,这种无意识的偏见也会蔓延到 ML 模型中。
收集和整理各种训练数据的步骤
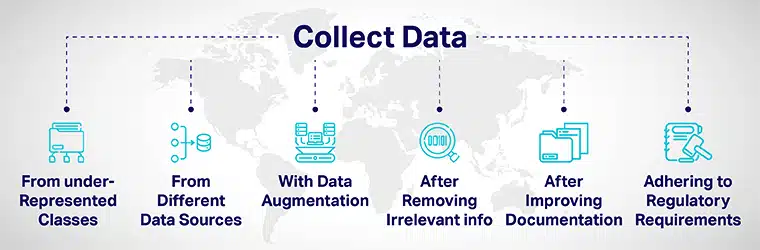
数据多样性 可以通过以下方式实现:
- 深思熟虑地从代表性不足的类中添加更多数据,并将您的模型暴露给不同的数据点。
- 通过从不同的数据源收集数据。
- 通过数据扩充或人为操作数据集来增加/包含与原始数据点明显不同的新数据点。
- 在为 AI 开发过程雇用申请人时,从申请中删除所有与工作无关的信息。
- 通过改进模型开发和评估的文档来提高透明度和问责制。
- 引入法规以建立多样性和 人工智能的包容性 来自基层的制度。 各国政府制定了指导方针,以确保多样性并减轻可能带来不公平结果的人工智能偏见。
[另请阅读: 了解有关 AI 训练数据收集过程的更多信息 ]
结论
目前,只有少数大型科技公司和学习中心专门参与开发人工智能解决方案。 这些精英空间充斥着排斥、歧视和偏见。 然而,这些是正在开发人工智能的空间,这些先进人工智能系统背后的逻辑充满了代表性不足的群体所承受的同样的偏见、歧视和排斥。
在讨论多样性和非歧视时,重要的是要质疑其受益的人和受其伤害的人。 我们还应该看看它让谁处于劣势——通过强加“正常”人的想法,人工智能可能会让“其他人”处于危险之中。
在不承认权力关系、公平和正义的情况下讨论 AI 数据的多样性不会展示更大的图景。 为了充分了解人工智能训练数据的多样性范围以及人类和人工智能如何共同缓解这场危机, 联系 Shaip 的工程师. 我们拥有多元化的 AI 工程师,可以为您的 AI 解决方案提供动态和多样化的数据。


