
人工智能、大数据和机器学习继续影响着世界各地的政策制定者、企业、科学、媒体机构和各种行业。 报告显示,全球人工智能的采用率目前处于 在35 2022% – 比 4 年增长 2021%。 据报道,另有 42% 的公司正在探索人工智能为其业务带来的诸多好处。
为许多人工智能计划提供动力和 机器学习 解决方案是数据。 AI 只能和提供给算法的数据一样好。 低质量的数据可能导致低质量的结果和不准确的预测。
虽然人们对 ML 和 AI 解决方案的开发给予了很多关注,但缺乏对什么是高质量数据集的认识。 在这篇文章中,我们浏览时间轴 优质的人工智能训练数据 并通过对数据收集和培训的理解来确定人工智能的未来。
AI训练数据的定义
在构建 ML 解决方案时,训练数据集的数量和质量很重要。 机器学习系统不仅需要大量动态、无偏见且有价值的训练数据,而且还需要大量数据。
但什么是 AI 训练数据?
AI 训练数据是标记数据的集合,用于训练 ML 算法以做出准确的预测。 机器学习系统尝试识别和识别模式,理解参数之间的关系,做出必要的决定,并根据训练数据进行评估。
以自动驾驶汽车为例。 自动驾驶 ML 模型的训练数据集应包括汽车、行人、路牌和其他车辆的标记图像和视频。
简而言之,要提高 ML 算法的质量,您需要大量结构良好、带注释和标记的训练数据。
高质量训练数据的重要性及其演变
高质量的训练数据是 AI 和 ML 应用程序开发的关键输入。 数据是从各种来源收集的,并以不适合机器学习目的的无组织形式呈现。 高质量的训练数据——标记、注解和标记——始终采用有组织的格式——非常适合 ML 训练。
高质量的训练数据使 ML 系统更容易识别对象并根据预定特征对其进行分类。 如果分类不准确,数据集可能会产生不良模型结果。
人工智能训练数据的早期
尽管 AI 主导了当前的商业和研究领域,但在 ML 主导之前的早期 人工智能 完全不同。
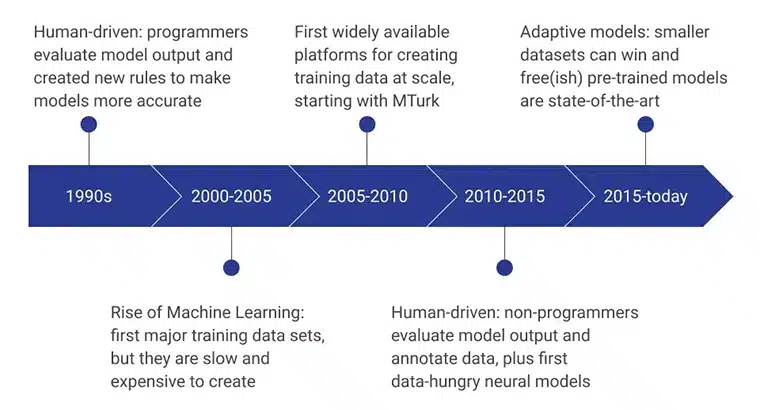
AI 训练数据的初始阶段由人类程序员提供支持,他们通过不断设计使模型更高效的新规则来评估模型输出。 在 2000 年至 2005 年期间,创建了第一个主要数据集,这是一个极其缓慢、依赖资源且成本高昂的过程。 它导致训练数据集被大规模开发,亚马逊的 MTurk 在改变人们对数据收集的看法方面发挥了重要作用。 同时,人工标注和注释也开始兴起。
接下来几年的重点是非程序员创建和评估数据模型。 目前,重点是使用高级训练数据收集方法开发的预训练模型。
数量超过质量
过去评估 AI 训练数据集的完整性时,数据科学家专注于 AI训练数据量 超过质量。
例如,人们普遍错误地认为大型数据库会提供准确的结果。 庞大的数据量被认为是数据价值的良好指标。 数量只是决定数据集价值的主要因素之一——数据质量的作用得到了认可。
意识到 数据质量 取决于数据的完整性、可靠性、有效性、可用性和及时性。 最重要的是,项目的数据适用性决定了所收集数据的质量。
由于训练数据不佳导致早期人工智能系统的局限性
训练数据不佳,加上缺乏先进的计算系统,是早期人工智能系统的几个未实现承诺的原因之一。
由于缺乏高质量的训练数据,ML 解决方案无法准确识别视觉模式,阻碍了神经研究的发展。 尽管许多研究人员确定了口语识别的前景,但由于缺乏语音数据集,语音识别工具的研究或开发未能取得成果。 开发高端人工智能工具的另一个主要障碍是计算机缺乏计算和存储能力。
向高质量训练数据的转变
人们对数据集质量很重要的认识发生了显着转变。 机器学习系统要准确模仿人类智能和决策能力,就必须依赖大量、高质量的训练数据。
将您的 ML 数据视为一项调查——数据越大 数据样本 尺寸越大,预测越好。 如果样本数据不包括所有变量,它可能无法识别模式或得出不准确的结论。
人工智能技术的进步和对更好训练数据的需求
 人工智能技术的进步增加了对高质量训练数据的需求。
人工智能技术的进步增加了对高质量训练数据的需求。更好的训练数据增加了可靠 ML 模型的机会的理解产生了更好的数据收集、注释和标记方法。 数据的质量和相关性直接影响人工智能模型的质量。
 人工智能技术的进步增加了对高质量训练数据的需求。
人工智能技术的进步增加了对高质量训练数据的需求。更加关注数据质量和准确性
为了让 ML 模型开始提供准确的结果,它以经过迭代数据提炼步骤的高质量数据集为基础。
例如,通过图片、视频或亲身接触,人类可能会在几天内认出特定品种的狗。 人类从他们的经验和相关信息中汲取灵感,以记住并在必要时提取这些知识。 然而,它对机器来说并不那么容易。 必须向机器提供该特定品种和其他品种的带有清晰注释和标签的图像(数百或数千),才能建立联系。
AI 模型通过将训练的信息与模型中呈现的信息相关联来预测结果 真实的世界. 如果训练数据不包含相关信息,则该算法将变得无用。
多样化和有代表性的训练数据的重要性
数据多样性的增加也提高了能力,减少了偏见,并促进了所有场景的公平代表性。 如果 AI 模型是使用同质数据集训练的,则可以确保新应用程序仅适用于特定目的并服务于特定人群。数据集可能偏向于特定的人口、种族、性别、选择和知识观点,这可能导致模型不准确。
重要的是要确保整个数据收集流程,包括选择主题池、管理、注释和标签,充分多样化、平衡并代表人口。
 数据多样性的增加也提高了能力,减少了偏见,并促进了所有场景的公平代表性。 如果 AI 模型是使用同质数据集训练的,则可以确保新应用程序仅适用于特定目的并服务于特定人群。
数据多样性的增加也提高了能力,减少了偏见,并促进了所有场景的公平代表性。 如果 AI 模型是使用同质数据集训练的,则可以确保新应用程序仅适用于特定目的并服务于特定人群。人工智能训练数据的未来
AI 模型未来的成功取决于用于训练 ML 算法的训练数据的质量和数量。 重要的是要认识到数据质量和数量之间的这种关系是特定于任务的并且没有明确的答案。
最终,训练数据集的充分性取决于它是否有能力为构建的目的可靠地良好运行。
数据收集和注释技术的进步
由于 ML 对输入的数据很敏感,因此简化数据收集和注释策略至关重要。 数据收集、管理、歪曲、不完整的测量、不准确的内容、数据重复和错误的测量中的错误都会导致数据质量不足。
通过数据挖掘、网络抓取和数据提取的自动化数据收集为更快的数据生成铺平了道路。 此外,预先打包的数据集可作为一种快速修复数据收集技术。
众包是另一种开创性的数据收集方法。 虽然无法保证数据的准确性,但它是收集公众形象的绝佳工具。 最后,专 数据采集 专家还提供用于特定目的的数据来源。
更加重视训练数据中的伦理考虑
随着人工智能的快速发展,出现了一些伦理问题,尤其是在训练数据收集方面。 训练数据收集中的一些伦理考虑包括知情同意、透明度、偏见和数据隐私。由于数据现在包括面部图像、指纹、录音和其他关键生物识别数据等所有内容,因此确保遵守法律和道德规范以避免代价高昂的诉讼和声誉受损变得至关重要。
未来有可能获得更高质量和多样化的培训数据
有巨大的潜力 优质多样的训练数据 将来。 由于对数据质量的认识以及满足 AI 解决方案质量需求的数据提供商的可用性。
目前的数据提供者擅长使用突破性的技术以合乎道德和合法的方式获取大量不同的数据集。 他们还有内部团队来标记、注释和呈现为不同 ML 项目定制的数据。
 随着人工智能的快速发展,出现了一些伦理问题,尤其是在训练数据收集方面。 训练数据收集中的一些伦理考虑包括知情同意、透明度、偏见和数据隐私。
随着人工智能的快速发展,出现了一些伦理问题,尤其是在训练数据收集方面。 训练数据收集中的一些伦理考虑包括知情同意、透明度、偏见和数据隐私。结论
与对数据和质量有深刻理解的可靠供应商合作非常重要 开发高端人工智能模型. Shaip 是首屈一指的注释公司,擅长提供满足您的 AI 项目需求和目标的定制数据解决方案。 与我们合作,探索我们带来的能力、承诺和协作。


