
大型语言模型最近在其高度胜任的用例 ChatGPT 一夜成名后获得了广泛关注。 看到 ChatGPT 和其他聊天机器人的成功,许多人和组织开始对探索为此类软件提供支持的技术产生兴趣。
大型语言模型是该软件背后的支柱,它支持各种自然语言处理应用程序的工作,如机器翻译、语音识别、问答和文本摘要。 让我们更多地了解 LLM 以及如何优化它以获得最佳结果。
什么是大型语言模型或 ChatGPT?
大型语言模型是一种机器学习模型,它利用人工神经网络和大量数据孤岛来为 NLP 应用程序提供动力。 在对大量数据进行训练后,LLM 获得了捕捉自然语言各种复杂性的能力,它进一步用于:
- 新文本的生成
- 文章和段落的总结
- 数据提取
- 重写或解释文本
- 数据分类
LLM 的一些流行示例是 BERT、Chat GPT-3 和 XLNet。 这些模型经过数亿文本的训练,可以为所有类型的不同用户查询提供有价值的解决方案。
大型语言模型的流行用例
以下是 LLM 的一些顶级和最普遍的用例:
文本生成
大型语言模型利用人工智能和计算语言学知识,自动生成自然语言文本,完成各种交际用户需求,如写文章、唱歌,甚至与用户聊天。
机器翻译
LLM 也可用于在任何两种语言之间翻译文本。 这些模型利用循环神经网络等深度学习算法来学习源语言和目标语言的语言结构。 因此,它们用于将源文本翻译成目标语言。
内容创建
现在,LLM 使机器能够创建连贯且合乎逻辑的内容,这些内容可用于生成博客文章、文章和其他形式的内容。 这些模型利用其广泛的深度学习知识,以独特且可读的格式为用户理解和构建内容。
情感分析
这是大型语言模型的一个令人兴奋的用例,其中训练模型以识别和分类标记文本中的情绪状态和情绪。 该软件可以检测积极、消极、中立和其他复杂情绪等情绪,有助于深入了解客户对不同产品和服务的意见和评论。
文本的理解、总结和分类
LLMs 为 AI 软件提供了一个实用的框架来理解文本及其上下文。 通过训练模型理解和分析大量数据,LLM 使 AI 模型能够理解、总结甚至对不同形式和模式的文本进行分类。
问题回答
大型语言模型使 QA 系统能够准确检测和响应用户的自然语言查询。 此用例最流行的应用程序之一是 ChatGPT 和 BERT,它们分析查询的上下文并通过大量文本进行搜索以找到用户查询的相关答案。
[另请阅读: 语言处理的未来:大型语言模型和示例 ]

LLM 成功的 3 个基本条件
必须准确满足以下三个条件才能提高效率并使您的大型语言模型成功:
存在用于模型训练的大量数据
LLM 需要大量数据来训练提供高效和最佳结果的模型。 有一些特定的方法,例如迁移学习和自我监督的预训练,LLM 可以利用这些方法来提高其性能和准确性。
构建神经元层以促进模型的复杂模式
大型语言模型必须包含经过专门训练以理解数据中复杂模式的神经元的各个层。 较浅层的神经元可以更好地理解复杂的模式。 该模型可以学习单词之间的关联、一起出现的主题以及词性之间的关系。
针对用户特定任务优化 LLM
可以通过更改层数、神经元和激活函数来针对特定任务调整 LLM。 例如,预测句子中以下单词的模型通常比设计用于从头生成新句子的模型使用更少的层和神经元。
大型语言模型的流行示例
以下是在不同垂直行业中广泛使用的 LLM 的几个突出示例:
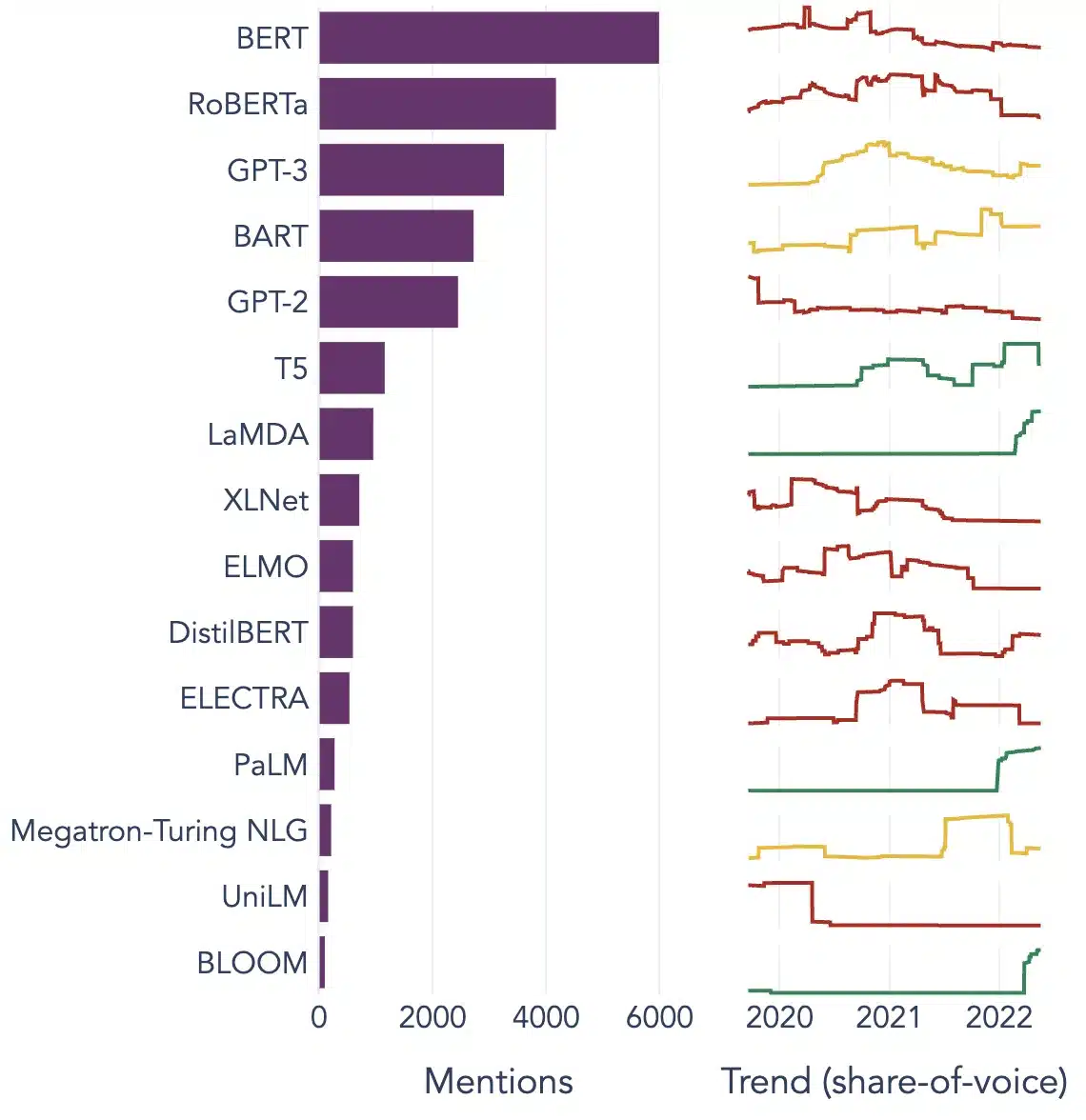
图片来源: 迈向数据科学
结论
法学硕士看到了通过提供强大而准确的语言理解能力和解决方案来提供无缝用户体验来彻底改变 NLP 的潜力。 然而,为了提高 LLM 的效率,开发人员必须利用高质量的语音数据来生成更准确的结果并生成高效的 AI 模型。
Shaip 是领先的 AI 技术解决方案之一,可提供 50 多种语言和多种格式的广泛语音数据。 了解有关 LLM 的更多信息,并从 今天的 Shaip 专家.


