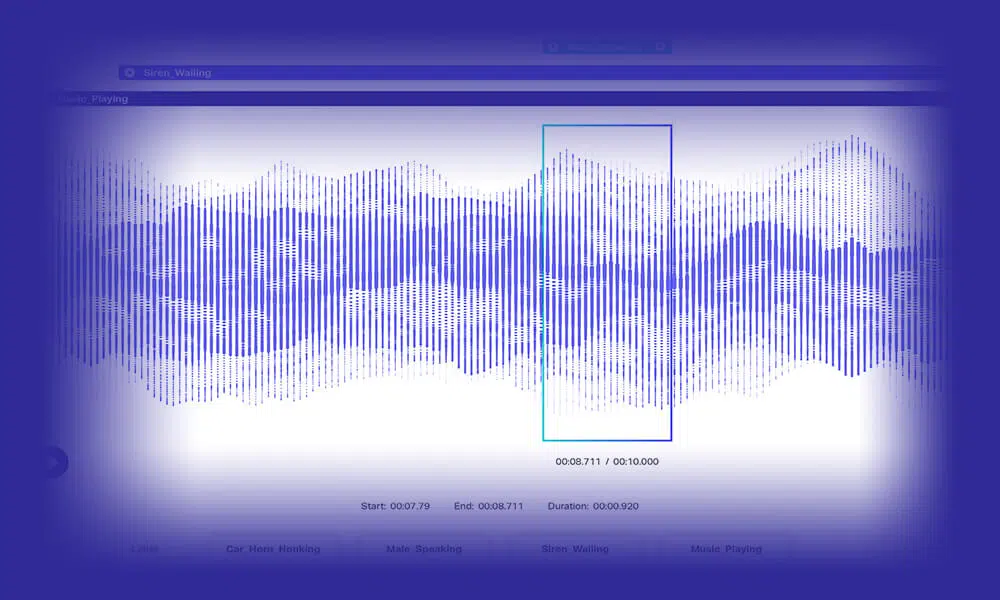

音频转录
通过输入大量精确转录的语音/音频数据来开发智能 NLP 模型。 在 Shaip,我们让您从更广泛的选择中进行选择,包括标准音频、逐字记录和多语言转录。 此外,您可以使用额外的说话者标识符和时间戳数据来训练模型。
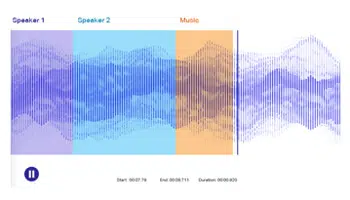
语音标签
语音或音频标签是一种标准注释技术,涉及分离声音并使用特定元数据进行标记。 该技术的本质涉及从一段音频中对声音进行本体识别,并对其进行准确注释,使训练数据集更具包容性

音频分类
语音注释公司使用它来训练 AI 使其完美,涉及根据内容分析录音。 通过音频分类,机器可以识别声音和声音,同时能够区分两者,作为更主动的培训制度的一部分。

多语言音频数据服务
只有当注释者可以相应地标记和分割它们时,收集多语言音频数据才有用。 这是多语言音频数据服务派上用场的地方,因为它们涉及基于语言的多样性对语音进行注释,由相关 AI 进行完美识别和解析

自然语言
发声
NLU 涉及注释人类语音以对最小的细节进行分类,如语义、方言、上下文、压力等。 这种带注释的数据形式在更好地训练虚拟助手和聊天机器人方面很有意义。
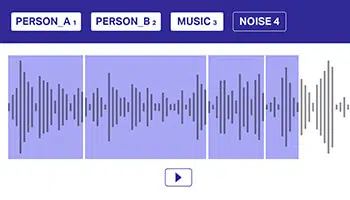
多标签
注解
通过使用多个标签来注释音频数据对于帮助模型区分重叠的音频源很重要。 在这种方法中,音频数据集可能属于一个或多个类,需要明确地传达给模型以进行更好的决策。

说话人分类
它涉及将输入音频文件拆分为与各个扬声器相关的同质片段。 分类意味着识别扬声器边界并将音频文件分组为段以确定不同扬声器的数量。 此过程有助于自动化对话分析和呼叫中心对话、医疗和法律对话以及会议的转录。
音标
与将音频转换为单词序列的常规转录不同,语音转录会记录单词的发音方式,并使用音标在视觉上表示声音。 音标可以更容易地注意到几种方言中同一语言的发音差异。

员工
专门和训练有素的团队:
- 30,000 多名数据创建、标签和 QA 协作者
- 有资质的项目管理团队
- 经验丰富的产品开发团队
- 人才库采购和入职团队

工艺
通过以下方式确保最高的流程效率:
- 稳健的 6 Sigma Stage-Gate 工艺
- 一个由 6 Sigma 黑带组成的专门团队——关键流程负责人和质量合规
- 持续改进和反馈循环

应用平台
获得专利的平台具有以下优势:
- 基于网络的端到端平台
- 无可挑剔的品质
- 更快的 TAT
- 无缝交付
员工
专门和训练有素的团队:
- 30,000 多名数据创建、标签和 QA 协作者
- 有资质的项目管理团队
- 经验丰富的产品开发团队
- 人才库采购和入职团队
工艺
通过以下方式确保最高的流程效率:
- 稳健的 6 Sigma Stage-Gate 工艺
- 一个由 6 Sigma 黑带组成的专门团队——关键流程负责人和质量合规
- 持续改进和反馈循环
应用平台
获得专利的平台具有以下优势:
- 基于网络的端到端平台
- 无可挑剔的品质
- 更快的 TAT
- 无缝交付

文字注解
特色服务
我们专注于通过注释详尽的数据集、使用实体注释、文本分类、情感注释和其他相关工具来准备文本数据训练。

图像注释
特色服务
我们以标记、分割图像数据集来训练计算机视觉模型而自豪。 一些相关技术包括边界识别和图像分类。

影片注解
特色服务
Shaip 提供用于训练计算机视觉模型的高端视频标记服务。 目的是使数据集可用于模式识别、对象检测等工具。


