



边界框
可以说是最可靠的视频标记技术,边界框注释涉及构思虚构的矩形来检测对象。

多边形注释
对于场景和对象分类,如果有不规则形状的实体在玩,多边形注释就派上用场了,因为它比边界框更准确。

语义分割
如果您想开发更有针对性和更准确的计算机视觉 AI,您可能需要考虑语义分割,这涉及在像素级别对图像进行分类。

关键点注释
像人脸检测这样的生物识别安全设置可以从 Keypoint 注释中受益,该注释侧重于标记用户表情、特定的面部标记(如嘴唇、鼻子、眼睛),甚至是细胞级别的注释。

3D 长方体注释
可能是边界框注释的更明确版本,3D 长方体用于识别和标记三维对象,而不是二维边界框提供的二维对象。

线和折线注释
这种技术最适用于需要对标记实体采取更平面方法的垂直行业。 它用于注释管道、道路、铁路和有关道路标记、车道等的数据集。

帧分类
对于涉及 YouTube 视频注释的数据工作流,我们将帧分类作为首选的注释方式。 这使您可以使视频更易于导航,并能够跳帧并提供更好的控制。
视频转录
如果您想更好地参与视频,我们建议将视频转录作为注释的补充形式,最适合将相关视频的音频片段翻译成文本。

骨架注释
如果您计划开发用于安全应用程序、健身和运动分析的模型,我们建议并部署骨骼注释以识别和标记数据集,重点是身体对齐和定位。

在客舱司机监控
注释了数百小时的驾驶员和车内视频片段。 每个视频都包含带有面部特征运动的完整注释剪辑,以及用于准确监控驾驶员行为并在观察到偏差时发出警告的车内场景。

零售人工智能
视频注释也有助于零售店了解消费者行为。 通过我们带注释的视频,可以轻松设计应用程序来跟踪购物者的活动、了解购买决策和识别盗窃行为。

交通监控
视频注释在开发高质量的监控应用程序中发挥着重要作用。 通过注释所需对象,我们已经成功地注释了数百小时的监控和闭路电视视频,具有更高的分辨率和细节。

人脸识别
Shaip 能够在人脸上应用关键点,用于开发用于开发面部识别应用程序的高端训练数据集。

车道检测
视频注释中的高级功能使我们能够筛选数小时的视频并使用折线注释来训练车辆检测车道、道路标记、车辆交通、改道、街道车道和方向。

计算机视觉与机器人
通过训练感知型机器人在无需人工交互的情况下使用、适应和响应环境,可以减少死亡和事故,从而提高生产力。

多标签注释
对于某些标记类别,您需要关注子类别以减少决策制定并使分析更加准确。 实例注释作为多标签视频注释的一部分,通过将车辆进一步分类为公共汽车、汽车等来帮助您实现相同的目标。

视频数据分析
如果您想在规划成熟的训练策略之前分析视频标记需求,您可以始终依赖我们的视频数据分析,该分析旨在帮助您更好地规划用例,规划出高度具体的目标,并最终让我们能够部署正确的注释技术。

自定义注解
一旦视频数据分析结束,我们甚至可以帮助您规划由正确的视频注释工具支持的自定义注释策略,即使您的用例非常难以捉摸并且需要进一步详细说明。

员工
专门和训练有素的团队:
- 30,000 多名数据创建、标签和 QA 协作者
- 有资质的项目管理团队
- 经验丰富的产品开发团队
- 人才库采购和入职团队

工艺
通过以下方式确保最高的流程效率:
- 稳健的 6 Sigma Stage-Gate 工艺
- 一个由 6 Sigma 黑带组成的专门团队——关键流程负责人和质量合规
- 持续改进和反馈循环

应用平台
获得专利的平台具有以下优势:
- 基于网络的端到端平台
- 无可挑剔的品质
- 更快的 TAT
- 无缝交付
员工
专门和训练有素的团队:
- 30,000 多名数据创建、标签和 QA 协作者
- 有资质的项目管理团队
- 经验丰富的产品开发团队
- 人才库采购和入职团队
工艺
通过以下方式确保最高的流程效率:
- 稳健的 6 Sigma Stage-Gate 工艺
- 一个由 6 Sigma 黑带组成的专门团队——关键流程负责人和质量合规
- 持续改进和反馈循环
应用平台
获得专利的平台具有以下优势:
- 基于网络的端到端平台
- 无可挑剔的品质
- 更快的 TAT
- 无缝交付

汽车行业
我们基于我们基于人工智能的高质量训练数据集,帮助汽车行业开发和部署可靠的自动驾驶和车载驾驶员监控工具。

医疗行业
我们通过利用视频注释来简化医疗系统内的医疗、成像、程序和流程,从而整合 AI 和机器学习功能。

生产
各行业正在利用视频注释的能力来训练和开发基于 AI 的工具,以加快生产速度、制定有时限的决策并简化制造过程。

监控
视频注释被用来检测物体,识别人类、汽车、树木、动物和其他物体,以开发增强的安全和监控工具。

文字注解
特色服务
我们专注于通过注释详尽的数据集、使用实体注释、文本分类、情感注释和其他相关工具来准备文本数据训练。
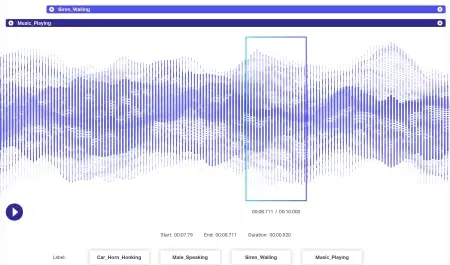
音频注释
特色服务
通过语音识别、说话人分类、情感识别等相关工具标记音频源、语音和特定于语音的数据集是我们的专长。

图像注释
特色服务
我们以标记、分割图像数据集来训练计算机视觉模型而自豪。 一些相关技术包括边界识别和图像分类。


