


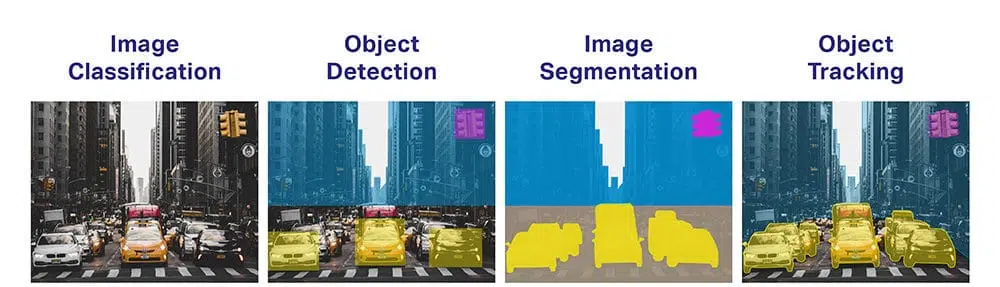
- 对象分类: 有哪些广泛的对象类别?
- 对象识别: 存在哪种类型的给定对象?
- 对象验证: 照片中的物体是什么?
- 对象检测: 照片中的物体在哪里?
- 对象地标检测: 照片中物体的关键点是什么?
- 对象分割: 哪些像素属于图像中的对象?
- 物体识别: 这张照片中有哪些物体,它们在哪里?

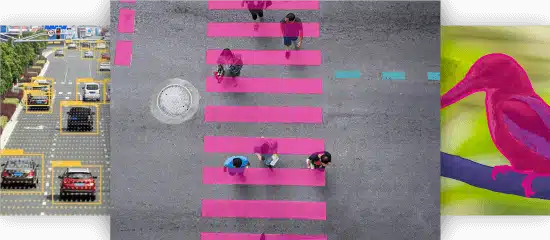

购物
注解
转录
用例
购物

图片集

影片集
注解

边界框
3D长方体
语义分割

多边形注释

地标注释

线段
转录

图像转录
视频转录
用例

影像分类
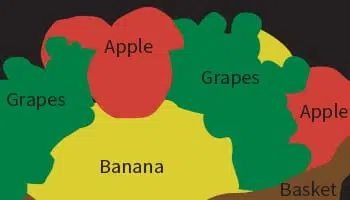
图像分割

图像关键点注释

视频分类
视频分割

- 使用案例: 车载ADAS模型
- 格式: 图片
- 容量: 455,000+
- 注解: 没有

- 使用案例: 地标检测
- 格式: 图片
- 容量: 80,000+
- 注解: 没有

- 使用案例: 行人追踪
- 格式: 视频
- 容量: 84,500+
- 注解: 是

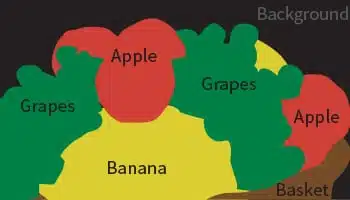
- 使用案例: 食品识别
- 格式: 图片
- 容量: 55,000+
- 注解: 是

医疗保健AI
训练 ML 模型以检测皮肤图像中的癌症痣或在 MRI 扫描或患者的 X 射线中发现症状。

人脸识别
训练 ML 模型以根据面部特征识别人物图像,并将其与面部档案数据库进行比较,以检测和标记人物。

地理空间应用
卫星图像和无人机摄影的注释,为地理处理准备数据集,并为 Geo.AI 注释 3D 点云。

增强现实技术
使用 AR 耳机,将虚拟对象放置在现实世界中。 它可以检测墙壁、桌面和地板等平面——这是建立深度和尺寸以及在物理世界中放置虚拟对象的非常关键的部分。

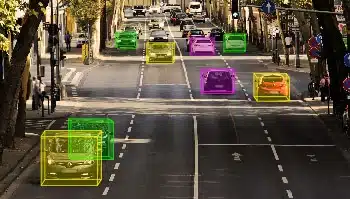
自动驾驶汽车
多个摄像头从不同角度拍摄视频,识别附近交通信号、道路、汽车、物体和行人的边界,训练自动驾驶汽车自动转向车辆,避免撞到障碍物,同时安全驾驶乘客。

零售/电子商务
借助零售业的计算机视觉,这些应用程序可以根据客户的购买模式提供个性化推荐,并加快货架管理、支付等业务运营速度。




员工
专门和训练有素的团队:
- 30,000 多名数据创建、标签和 QA 协作者
- 有资质的项目管理团队
- 经验丰富的产品开发团队
- 人才库采购和入职团队

工艺
通过以下方式确保最高的流程效率:
- 稳健的 6 Sigma Stage-Gate 工艺
- 一个由 6 Sigma 黑带组成的专门团队——关键流程负责人和质量合规
- 持续改进和反馈循环

应用平台
获得专利的平台具有以下优势:
- 基于网络的端到端平台
- 无可挑剔的品质
- 更快的 TAT
- 无缝交付
员工
专门和训练有素的团队:
- 30,000 多名数据创建、标签和 QA 协作者
- 有资质的项目管理团队
- 经验丰富的产品开发团队
- 人才库采购和入职团队
工艺
通过以下方式确保最高的流程效率:
- 稳健的 6 Sigma Stage-Gate 工艺
- 一个由 6 Sigma 黑带组成的专门团队——关键流程负责人和质量合规
- 持续改进和反馈循环
应用平台
获得专利的平台具有以下优势:
- 基于网络的端到端平台
- 无可挑剔的品质
- 更快的 TAT
- 无缝交付