


问答对
文字摘要
图片说明
音频生成
法学硕士数据评估
法学硕士数据比较
综合对话创建
图像摘要、评级和验证
问答对
创建问答对
关键字查询创建
顺序问答
RAG 问答验证
创建问答对

关键字查询创建

顺序问答

RAG 问答验证

文字摘要
段落总结
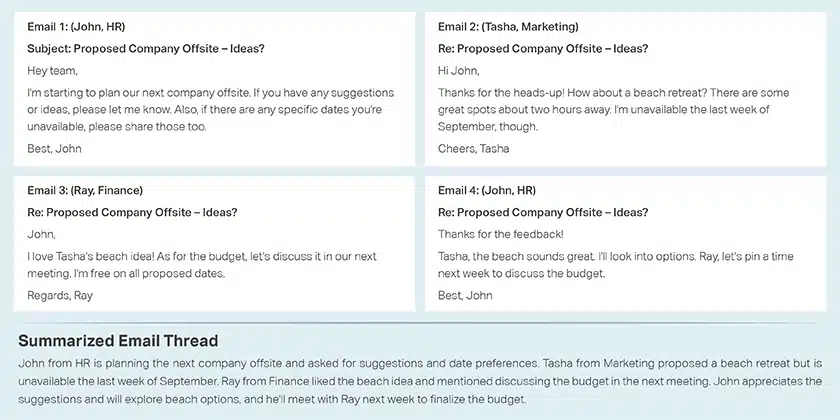
电子邮件摘要
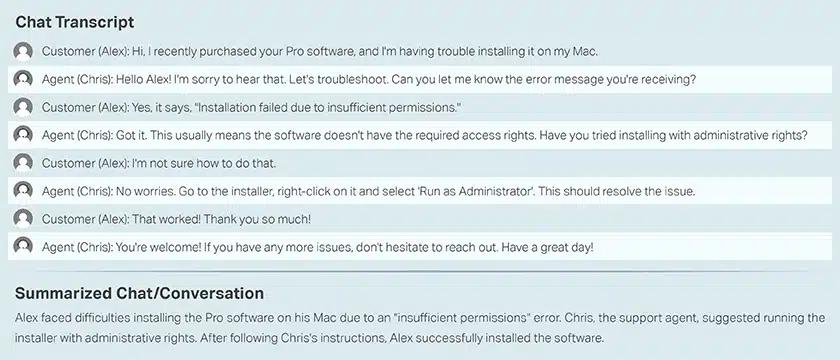
对话总结
段落总结

电子邮件摘要
对话总结
图片说明

音频生成

法学硕士数据评估

法学硕士数据比较

综合对话创建
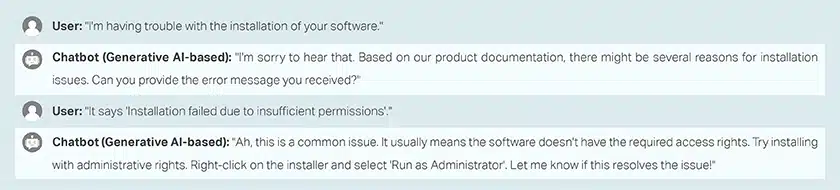
聊天机器人培训问答
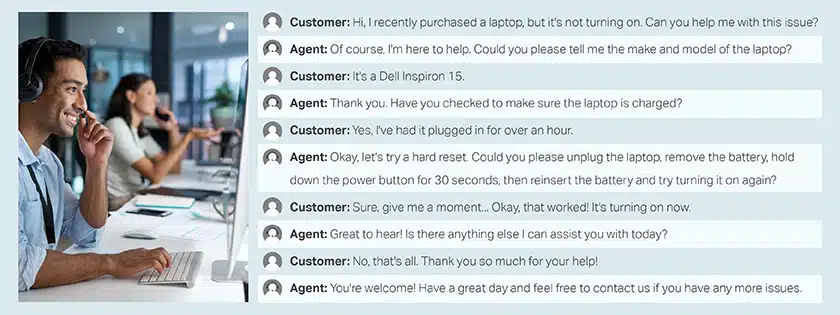
呼叫中心对话客户和代理
聊天机器人培训问答
呼叫中心对话客户和代理
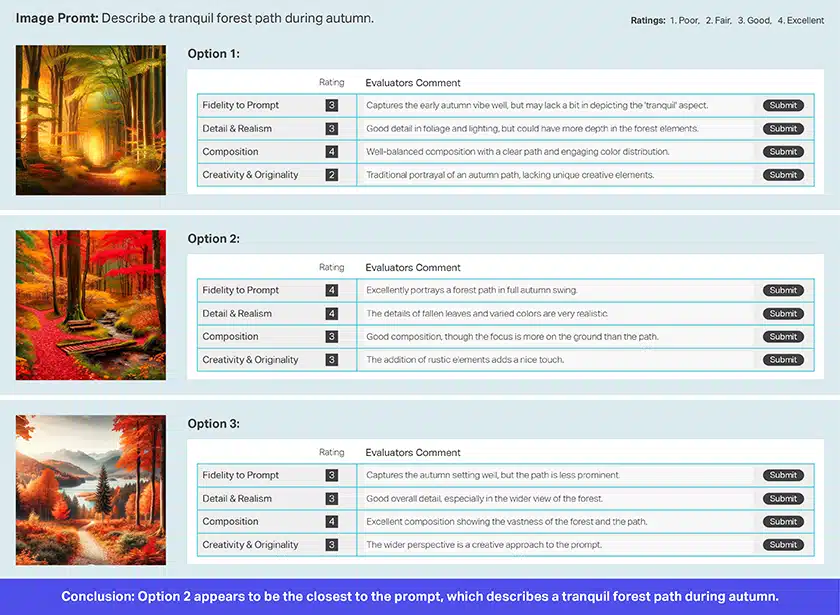
图像摘要、评级和验证
图像评级
图像验证
图像摘要
图像评级
图像验证
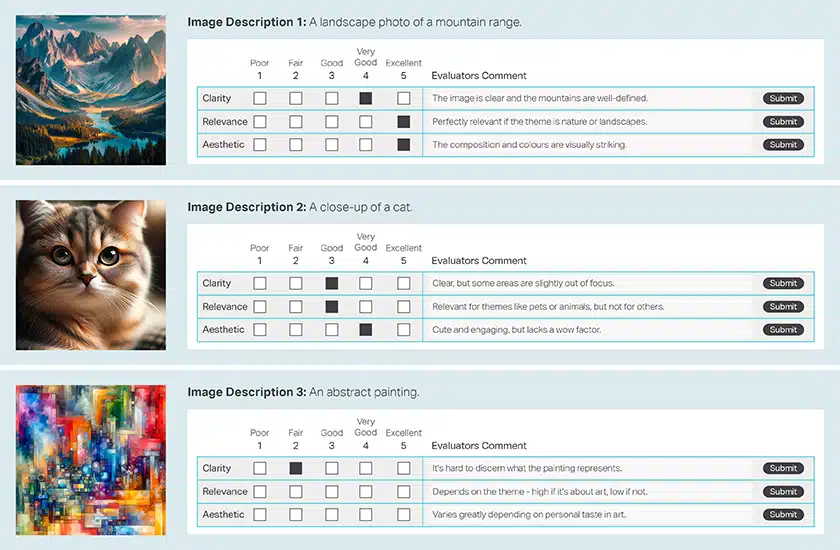
图像摘要




创建临床 NLP 是一项关键任务,需要大量的领域专业知识来解决。 我可以清楚地看到你在这方面领先谷歌几年。 我想和你一起工作并扩大你的规模。
Google,Inc. 副总经理
在开发医疗保健语音 API 期间,我的工程团队与 Shaip 的团队合作了 2 年以上。 他们在特定于医疗保健的 NLP 方面所做的工作以及他们能够使用复杂数据集实现的目标给我们留下了深刻的印象。
Google,Inc. 工程主管