





购物
注解
转录
购物

文字集

音频/语音收藏
注解
文字注解
音频/语音注释
转录
文字转录
音频/语音转录




对话式人工智能 / 聊天机器人训练
培训数字助理需要来自不同地域、语言、方言、设置和格式的大量高质量数据。 在 Shaip,我们为具有人在环的 AI 模型提供训练数据,这些模型具有所需的知识和领域专业知识,并且非常了解客户的特定需求。
情绪/意图
分析
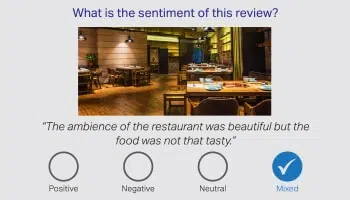
正确地说,仅靠文字无法传达整个故事,人类注释者有责任解释人类语言中的歧义。 因此,根据对话识别客户的情绪至关重要。 我们来自各个领域的语言专家可以解读产品评论、财经新闻和社交媒体中的细微差别。

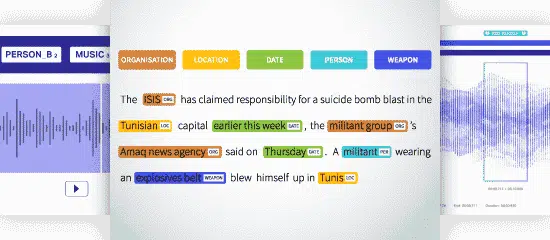
命名实体识别(NER)
命名实体识别 (NER) 正在识别、提取文本中的命名实体并将其分类为预定义的类别。 文本可以归类为地点、名称、组织、产品、数量、价值、百分比等。 使用 NER,您可以解决实际问题,例如文章中提到了哪些组织等。
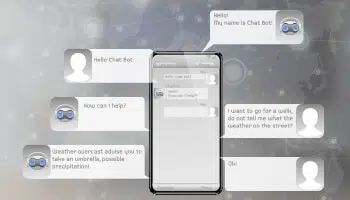
客户服务自动化
强大、训练有素的虚拟聊天机器人或数字助理彻底改变了客户与卖家沟通的方式,显着改善了客户体验。

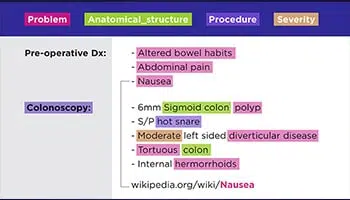
文字转录
从医生的手写处方到电话会议记录,我们的专家可以将任何形式的数据数字化,即存档文件、法律合同、患者健康记录等。
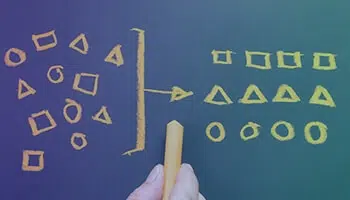
内容分类
分类也称为分类或标记是将文本分类为有组织的组并根据其感兴趣的特征对其进行标记的过程。

话题分析
主题分析或主题标签是通过识别正在考虑的重复主题/主题来识别和提取给定文本的含义。
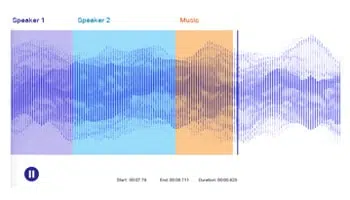
音频转录
转录演讲/播客/研讨会,将对话转换为文本。 利用人类准确注释音频/语音文件以准确训练 NLP 模型。

音频分类
对声音或话语进行分类,以根据语言、方言、语义、词典等对语音/音频进行分类。

员工
专门和训练有素的团队:
- 30,000 多名数据创建、标签和 QA 协作者
- 有资质的项目管理团队
- 经验丰富的产品开发团队
- 人才库采购和入职团队

工艺
通过以下方式确保最高的流程效率:
- 稳健的 6 Sigma Stage-Gate 工艺
- 一个由 6 Sigma 黑带组成的专门团队——关键流程负责人和质量合规
- 持续改进和反馈循环

应用平台
获得专利的平台具有以下优势:
- 基于网络的端到端平台
- 无可挑剔的品质
- 更快的 TAT
- 无缝交付



创建临床 NLP 是一项关键任务,需要大量的领域专业知识来解决。 我可以清楚地看到你在这方面领先谷歌几年。 我想和你一起工作并扩大你的规模。
Google,Inc. 副总经理
在开发医疗保健语音 API 期间,我的工程团队与 Shaip 的团队合作了 2 年以上。 他们在特定于医疗保健的 NLP 解决方案中所做的工作以及他们能够使用复杂数据集实现的目标给我们留下了深刻的印象。
Google,Inc. 工程主管