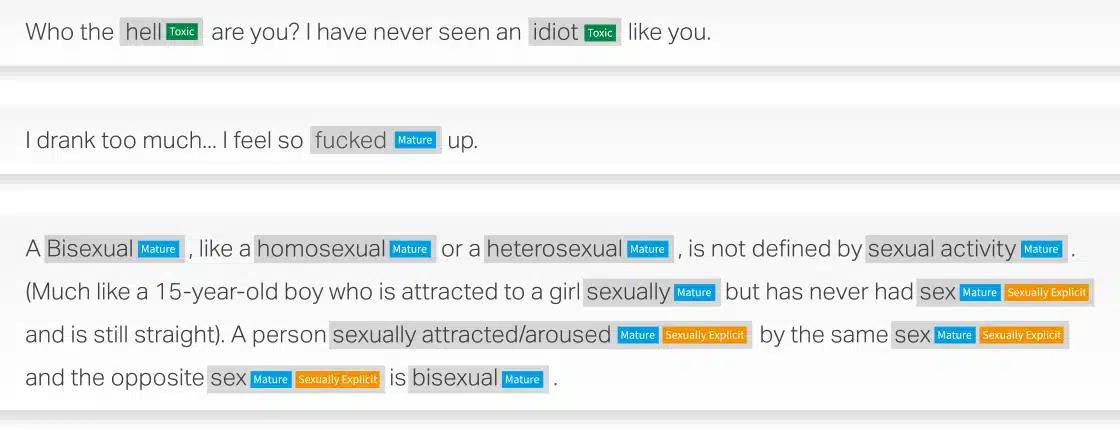
案例研究:内容审核30K+ 文档 web 报废和注释内容审核 下载案例研究 对 AI 驱动的内容审核的需求不断增加努力保护我们连接和交流的在线空间。 随着社交媒体使用量的持续增长,网络欺凌问题已经浮出水面平台努力的重大障碍确保安全的在线空间。 一个惊人的38% 的人遇到过这种情况每天的有害行为,强调对创造性的迫切需求内容审核方法。今天的组织依赖于使用人工智能解决持久性问题主动解决网络欺凌问题。 网络安全:Facebook 第四季度社区标准执行报告披露——对 4 万条欺凌和骚扰内容采取行动,主动检测率为 6.3% Education: A 2021 研究发现 36.5%美国 % 的学生年龄介于 12和17 年在他们上学期间曾经历过网络欺凌。 根据 2020 年的一份报告,4.07 年全球内容审核解决方案市场价值 2019 亿美元,预计到 11.94 年将达到 2027 亿美元,复合年增长率为 14.7%。 真实世界的解决方案调节全球对话的数据客户正在开发一个强大的自动化内容审核机器学习其云产品的模型,为此他们正在寻找特定领域的供应商可以帮助他们提供准确的训练数据。利用我们在自然语言处理 (NLP) 方面的广泛知识,我们协助客户收集、分类和注释了 30,000 多份英语和西班牙语文档,以构建自动内容审核机器学习模型,分为有毒、成人或色情内容类别。 市场问题 从优先域中抓取 30,000 份西班牙语和英语文档将收集到的内容分为短、中、长段将编译后的数据标记为有毒、成人或露骨色情内容确保高质量的注释,准确率至少为 90%。 解决方案 Web 从 BFSI、医疗保健、制造、零售中分别收集了 30,000 份西班牙语和英语文档。 内容进一步分为短、中、长文档 成功将分类内容标记为有毒、成人或露骨色情内容为了达到 90% 的质量,Shaip 实施了两层质量控制流程:» 级别 1:质量保证检查:100% 的文件进行验证。» 级别 2:关键质量分析检查:Shaips 的 CQA 团队评估 15%-20% 的回顾性样本。 结果 培训数据有助于构建自动化内容审核 ML 模型,该模型可以产生多种有益于维护更安全的在线环境的结果。 一些主要成果包括:处理大量数据的效率确保统一执行适度政策的一致性适应不断增长的用户群和内容量的可扩展性实时审核可以识别和删除生成的潜在有害内容通过减少对人类主持人的依赖来提高成本效益 内容审核示例 加速您的对话式 AI 应用程序开发 100% 索取方案演示 创建临床 NLP 是一项关键任务,需要大量的领域专业知识来解决。 我可以清楚地看到你在这方面领先谷歌几年。 我想和你一起工作并扩大你的规模。 Google,Inc. 副总经理 在开发医疗保健语音 API 期间,我的工程团队与 Shaip 的团队合作了 2 年以上。 他们在特定于医疗保健的 NLP 方面所做的工作以及他们能够使用复杂数据集实现的目标给我们留下了深刻的印象。 Google,Inc. 工程主管 告诉我们我们如何为您的下一个 AI 计划提供帮助。 联系我们