
克服人工智能发展障碍的关键:更可靠的数据
今天,普通人现在口袋里的计算能力是美国宇航局 1969 年登月时的数百万倍。 同样无处不在的设备,方便地展示了丰富的计算能力,也满足了人工智能黄金时代的另一个先决条件:大量数据。 根据信息过载研究小组的见解,世界上 90% 的数据是在过去两年中创建的。 现在,计算能力的指数级增长最终与数据生成的同样快速增长相融合,人工智能数据创新正在爆炸式增长,以至于一些专家认为将启动第四次工业革命。
来自美国国家风险投资协会的数据显示,人工智能领域在 6.9 年第一季度的投资达到创纪录的 2020 亿美元。人工智能工具的潜力不难看出,因为它已经在我们身边被挖掘。 AI 产品的一些更明显的用例是我们最喜欢的应用程序(如 Spotify 和 Netflix)背后的推荐引擎。 虽然发现一个新的艺术家来听或一个新的电视节目来狂欢很有趣,但这些实现的风险相当低。 其他算法对考试成绩进行评分——部分确定学生被大学录取的位置——还有一些算法筛选候选人简历,决定哪些申请人获得特定工作。 一些人工智能工具甚至可以产生生死攸关的影响,例如筛查乳腺癌的人工智能模型(其表现优于医生)。
尽管 AI 开发的真实案例和竞争创建下一代转型工具的初创公司数量稳步增长,但有效开发和实施的挑战仍然存在。 特别是,AI 输出仅在输入允许的范围内准确,这意味着质量至关重要。

驾驭复杂的合规性需求
似乎找到高质量的数据还不够困难,一些从 AI 数据创新中获益最多的行业也受到最严格的监管。 医疗保健可能是最好的例子,虽然 HIT Infrastructure 的一项调查发现,91% 的业内人士认为该技术可以改善获得护理的机会,但由于 75% 的人将其视为对患者安全和隐私的威胁,这种乐观情绪有所减弱- 患者并不是唯一面临风险的人。
通过《健康保险流通与责任法案》颁布的全面法规现在与各种本地数据合规障碍交叉,例如欧洲的通用数据保护条例、美国的加利福尼亚消费者隐私法和新加坡的个人数据保护法。 更多的地方法规将加入这些地方法规,并且随着远程医疗成为更重要的医疗保健数据来源,法规可能会更严格地控制传输中的患者数据。 因此,Shaip 安全且合规的云平台将被证明是一种更有价值的收集和访问医疗保健数据以训练 AI 产品的手段。
个人可识别信息可能对您的 AI 开发构成重大威胁,但如果无法提供只有多样化训练数据才能提供的准确结果,即使是完全合规的实施也存在风险。 《美国医学会杂志》2020 年的一项研究表明,医学领域的机器学习算法最常使用来自加利福尼亚、纽约和马萨诸塞州患者的数据进行训练。 鉴于这些患者只占美国人口的不到五分之一,更不用说世界其他地方了,很难想象这些模型除了产生有偏见的结果之外,还能产生什么结果。

 Shaip 认识到保护合规的、地域多样的信息的困难,提供来自各种地区的许可医疗保健数据,专门策划以构建准确的算法为目的。 这些数据以文本形式出现,例如医疗记录或理赔信息、CT 扫描等医学诊断成像、医生口述或医患对话等音频,甚至 MRI 结果中的视频。 它还完全去标识化和匿名化,保护您的组织免受道德和财务影响,这些影响可能会因违反越来越多的管理国内和国际来源数据的法规而产生。
Shaip 认识到保护合规的、地域多样的信息的困难,提供来自各种地区的许可医疗保健数据,专门策划以构建准确的算法为目的。 这些数据以文本形式出现,例如医疗记录或理赔信息、CT 扫描等医学诊断成像、医生口述或医患对话等音频,甚至 MRI 结果中的视频。 它还完全去标识化和匿名化,保护您的组织免受道德和财务影响,这些影响可能会因违反越来越多的管理国内和国际来源数据的法规而产生。
克服人工智能发展障碍
无论在哪个行业,人工智能的开发工作都存在重大障碍,从一个可行的想法到成功的产品的过程充满了困难。 在获取正确数据的挑战和将其匿名化以符合所有相关法规的需求之间,感觉实际上构建和训练算法是容易的部分。
为了让您的组织在设计突破性的新 AI 开发的工作中获得一切必要的优势,您需要考虑与像 Shaip 这样的公司合作。 Chetan Parikh 和 Vatsal Ghiya 创立了 Shaip,旨在帮助公司设计可以改变美国医疗保健的各种解决方案。经过 16 年的经营,我们公司已经发展到拥有 600 多名团队成员,我们已经与数百名客户将引人注目的想法转化为 AI 解决方案。
通过我们的人员、流程和平台为您的组织工作,您可以立即获得以下四个好处,并推动您的项目取得成功:
1. 解放数据科学家的能力
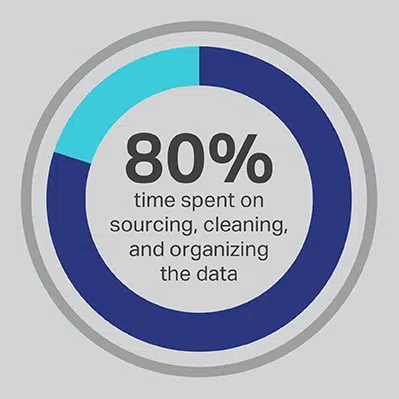
AI 开发过程需要花费大量时间,这是无可避免的,但您始终可以优化团队花费最多时间执行的功能。 您聘请数据科学家是因为他们是高级算法和机器学习模型开发方面的专家,但研究一致表明,这些员工实际上将 80% 的时间用于采购、清理和组织将为项目提供动力的数据。 超过四分之三 (76%) 的数据科学家报告说,这些平凡的数据收集过程也恰好是他们工作中最不喜欢的部分,但对高质量数据的需求只留下了 20% 的时间用于实际开发,这是对于许多数据科学家来说,这是最有趣和最能激发智力的工作。 通过通过第三方供应商(如 Shaip)采购数据,公司可以让其昂贵且才华横溢的数据工程师将他们的工作外包为数据管理员,而将时间花在人工智能解决方案中可以产生最大价值的部分。
2. 取得更好结果的能力
 许多 AI 开发领导者决定使用开源或众包数据来减少开支,但从长远来看,这种决定几乎总是导致成本增加。 这些类型的数据很容易获得,但它们无法与精心策划的数据集的质量相匹配。 众包数据尤其充斥着错误、遗漏和不准确之处,虽然这些问题有时可以在开发过程中在工程师的监督下解决,但如果您开始使用更高级别的数据,则不需要额外的迭代。 - 质量数据从一开始。
许多 AI 开发领导者决定使用开源或众包数据来减少开支,但从长远来看,这种决定几乎总是导致成本增加。 这些类型的数据很容易获得,但它们无法与精心策划的数据集的质量相匹配。 众包数据尤其充斥着错误、遗漏和不准确之处,虽然这些问题有时可以在开发过程中在工程师的监督下解决,但如果您开始使用更高级别的数据,则不需要额外的迭代。 - 质量数据从一开始。
依赖开源数据是另一种常见的捷径,但也有一些陷阱。 缺乏差异化是最大的问题之一,因为使用开源数据训练的算法比建立在许可数据集上的算法更容易复制。 通过这条路线,您会邀请该领域其他进入者的竞争,他们可以随时降低您的价格并抢占市场份额。 当您依赖 Shaip 时,您将访问由熟练管理的劳动力收集的最高质量的数据,我们可以授予您自定义数据集的独家许可,以防止竞争对手轻松地重新创建您来之不易的知识产权。
3. 接触经验丰富的专业人士
 即使您的内部名册包括熟练的工程师和才华横溢的数据科学家,您的 AI 工具也可以从只有通过经验而来的智慧中受益。 我们的主题专家在他们的领域率先实施了许多 AI,并在此过程中吸取了宝贵的经验教训,他们的唯一目标是帮助您实现自己的目标。
即使您的内部名册包括熟练的工程师和才华横溢的数据科学家,您的 AI 工具也可以从只有通过经验而来的智慧中受益。 我们的主题专家在他们的领域率先实施了许多 AI,并在此过程中吸取了宝贵的经验教训,他们的唯一目标是帮助您实现自己的目标。
通过领域专家为您识别、组织、分类和标记数据,您知道用于训练算法的信息可以产生最佳结果。 我们还定期进行质量保证,以确保数据符合最高标准,并且不仅在实验室中,而且在现实世界中都能按预期执行。
4. 加速开发时间表
AI 开发不会在一夜之间发生,但当您与 Shaip 合作时,它会发生得更快。 内部数据收集和注释造成了严重的操作瓶颈,阻碍了其余的开发过程。 与 Shaip 合作可让您即时访问我们庞大的即用型数据库,我们的专家将能够利用我们深厚的行业知识和全球网络获取您需要的任何类型的额外输入。 没有采购和注释的负担,您的团队可以立即开始实际开发工作,我们的训练模型可以帮助识别早期不准确之处,以减少实现准确度目标所需的迭代。
如果您不准备外包数据管理的所有方面,Shaip 还提供了一个基于云的平台,可帮助团队更有效地生成、更改和注释不同类型的数据,包括对图像、视频、文本和音频的支持. ShaipCloud 包括各种直观的验证和工作流程工具,例如用于跟踪和监控工作负载的专利解决方案、用于转录复杂和困难的录音的转录工具以及用于确保不妥协质量的质量控制组件。 最重要的是,它是可扩展的,因此它可以随着项目的各种需求的增加而增长。
AI 创新的时代才刚刚开始,我们将在未来几年看到令人难以置信的进步和创新,这些进步和创新有可能重塑整个行业甚至改变整个社会。 在 Shaip,我们希望利用我们的专业知识成为一股变革力量,帮助世界上最具革命性的公司利用人工智能解决方案的力量来实现雄心勃勃的目标。
我们在医疗保健应用程序和对话式 AI 方面拥有丰富的经验,但我们也拥有为几乎任何类型的应用程序训练模型的必要技能。 有关 Shaip 如何帮助您将项目从创意变为实施的更多信息,请查看我们网站上提供的许多资源或立即与我们联系。
