



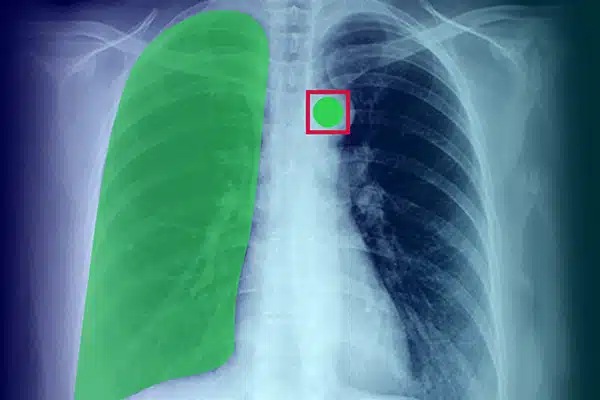
图像注释
通过注释 X 射线、CT 扫描和 MRI 的视觉数据来增强医疗 AI。确保人工智能模型在专家数据标签的指导下在诊断和治疗中表现出色。通过卓越的成像洞察力获得更好的患者治疗效果。
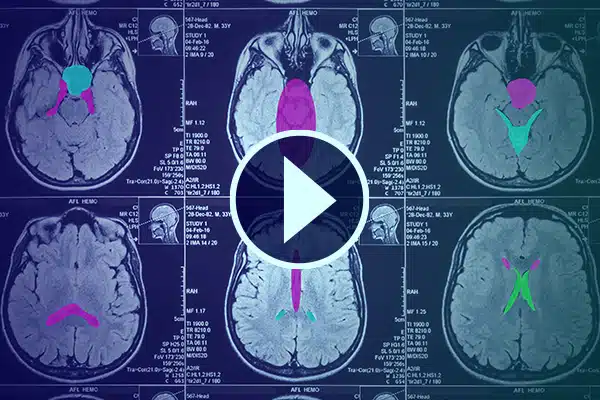
影片注解
通过详细的视频注释推进医疗保健领域的人工智能。通过医疗镜头中的分类和分割来强化人工智能学习。改进您的手术人工智能和患者监测,以改善医疗服务和诊断。
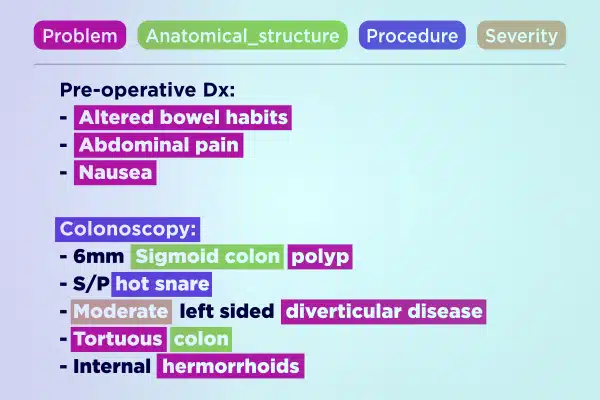
文字注解
利用经过专业注释的文本数据简化医疗人工智能开发。快速解析和丰富大量文本,从手写笔记到保险报告。确保为医疗保健进步提供准确且可行的见解。

音频注释
利用 NLP 专业知识准确注释和标记医疗音频数据。打造用于无缝临床操作的语音辅助系统,并将人工智能集成到各种声控医疗保健产品中。通过专家音频数据管理提高诊断精度。

医疗编码
通过人工智能医疗编码将其转换为通用代码,从而简化医疗文档。通过医疗记录编码方面的尖端人工智能辅助,确保准确性、提高计费效率并支持无缝医疗保健服务交付。

阶段1: 技术领域专业知识(了解范围和注释指南)

阶段2: 为项目培训适当的资源

阶段3: 注释文档的反馈周期和质量保证
放射线学
我们的放射学图像注释服务增强了人工智能诊断能力,并增加了一层专业知识。每张 X 射线、MRI 和 CT 扫描均经过主题专家的精心标记和审查。训练和审查的这一额外步骤增强了人工智能发现异常和疾病的能力。它提高了交付给客户之前的准确性。

心脏病
我们以心脏病学为中心的图像注释增强了人工智能诊断。我们聘请了心脏病学专家来标记复杂的心脏相关图像并训练我们的人工智能模型。在我们将数据发送给客户之前,这些专家会审查每张图像以确保一流的准确性。这一过程使人工智能能够更准确地检测心脏状况。
牙医行业
我们的牙科图像注释服务对牙科图像进行标记,以增强人工智能诊断工具。通过准确识别蛀牙、排列问题和其他牙齿状况,我们的中小企业使人工智能能够改善患者的治疗效果,并支持牙医进行精确的治疗计划和早期检测。


















员工
专门和训练有素的团队:
- 30,000 多名数据创建、标签和 QA 协作者
- 有资质的项目管理团队
- 经验丰富的产品开发团队
- 人才库采购和入职团队

工艺
通过以下方式确保最高的流程效率:
- 稳健的 6 Sigma Stage-Gate 工艺
- 一个由 6 Sigma 黑带组成的专门团队——关键流程负责人和质量合规
- 持续改进和反馈循环

应用平台
获得专利的平台具有以下优势:
- 基于网络的端到端平台
- 无可挑剔的品质
- 更快的 TAT
- 无缝交付



