
什么是机器学习中的文本注释?
机器学习中的文本注释是指向原始文本数据添加元数据或标签,以创建用于训练、评估和改进机器学习模型的结构化数据集。 这是自然语言处理 (NLP) 任务中的关键一步,因为它有助于算法根据文本输入理解、解释和做出预测。
文本注释很重要,因为它有助于弥合非结构化文本数据和结构化机器可读数据之间的差距。 这使得机器学习模型能够从带注释的示例中学习和概括模式。
高质量的注释对于构建准确且稳健的模型至关重要。 这就是为什么在文本注释中仔细关注细节、一致性和领域专业知识至关重要。
文本注释的类型

训练 NLP 算法时,必须拥有适合每个项目独特需求的大型带注释文本数据集。 因此,对于想要创建此类数据集的开发人员,这里简单概述了五种流行的文本注释类型。

情感注解
情感注释识别文本的潜在情感、观点或态度。 注释者用积极、消极或中性情绪标签来标记文本片段。 情感分析是这种注释类型的关键应用,广泛应用于社交媒体监控、客户反馈分析和市场研究。
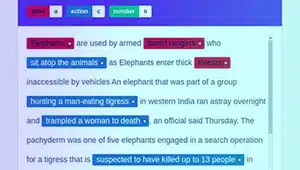
意图注释
意图注释旨在捕获给定文本背后的目的或目标。 在这种类型的注释中,注释者将标签分配给代表特定用户意图的文本段,例如询问信息、请求某事或表达偏好。
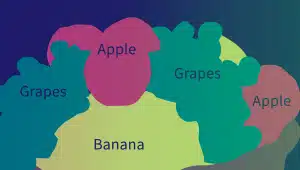
语义注释
语义注释识别单词、短语和句子之间的含义和关系。 注释者使用文本分割、文档分析和文本提取等各种技术来标记和分类文本元素的语义属性。

实体注解
实体注释对于创建聊天机器人训练数据集和其他 NLP 数据至关重要。 它涉及在文本中查找和标记实体。 实体注释的类型包括:

语言注释
语言注释涉及语言的结构和语法方面。 它包含各种子任务,例如词性标记、句法分析和形态分析。

保险
文本注释可帮助保险公司分析客户反馈、处理索赔和检测欺诈。 通过使用在带注释的数据集上训练的人工智能模型,保险公司可以:

银行业
文本注释有助于改善银行业的客户服务、欺诈检测和文档分析。 经过注释数据训练的人工智能系统可以:

电信
文本注释使电信公司能够增强客户支持、监控社交媒体和管理网络问题。 在带注释的数据集上训练的机器学习模型可以:
如何注释文本数据?
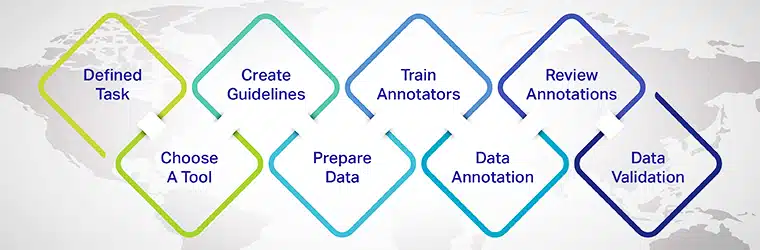
- 定义标注任务: 确定您想要解决的特定 NLP 任务,例如情感分析、命名实体识别或文本分类。
- 选择合适的标注工具:选择符合您的项目需求并支持所需注释类型的文本注释工具或平台。
- 创建注释指南:制定清晰一致的指南供注释者遵循,确保高质量和准确的注释。
- 选择并准备数据:收集原始文本数据的多样化且具有代表性的样本,供注释者处理。
- 训练和评估注释者:为注释者提供培训和持续反馈,确保注释过程的一致性和质量。
- 注释数据:注释者根据定义的准则和注释类型来标记文本。
- 检查并完善注释:定期检查和完善注释,解决任何不一致或错误,并迭代改进数据集。
- 分割数据集:将标注数据分为训练集、验证集和测试集,用于训练和评估机器学习模型。
夏普能为您做什么?
Shaip 提供量身定制的服务 文本标注解决方案 为各行业的人工智能和机器学习应用提供支持。 Shaip 专注于高质量和准确的注释,经验丰富的团队和先进的注释平台可以处理多样化的文本数据。
无论是情感分析、命名实体识别还是文本分类,Shaip 都能提供自定义数据集来帮助增强 AI 模型的语言理解和性能。
相信 Shaip 能够简化您的文本注释流程,并确保您的 AI 系统充分发挥潜力。

