
你有没有想过当你说“嘿 Siri”或“Alexa”时,聊天机器人和虚拟助手是如何醒来的? 这是因为软件中嵌入的文本话语收集或触发词,一旦听到编程的唤醒词就会激活系统。
然而,创建声音和话语数据的整个过程并不是那么简单。 这是一个必须使用正确的技术来获得预期结果的过程。 因此,本博客将分享创建与对话 AI 无缝协作的良好话语/触发词的途径。
什么是话语?
话语可以被称为用于激活人工智能模型的短语或触发词。 当您的 AI 模型检测到它的唤醒词时,它会自动开始记录用户的下一个请求并以适当的操作或回复进行回复。
Utterance 使用深度学习的概念来教软件如何识别唤醒词。 一旦唤醒词激活软件,系统就会开始捕获、解码和服务请求。 不使用时,系统会被动地持续监听触发词。
为了让您的 AI 软件获得准确的结果,为每个意图捕获大量不同的话语至关重要。 它有助于更好地训练 AI 模型。
[另请阅读: 你想知道 Siri 和 Alexa 是如何理解你的吗?]
创建话语存储库时要记住的要点
既然我们知道训练对 AI 模型很重要,接下来要知道的是如何为 AI 模型提供话语。 通常,会创建一个话语库来训练会话 AI。
但是,在构建话语存储库时需要记住很多事情。 以下是需要考虑的事项:
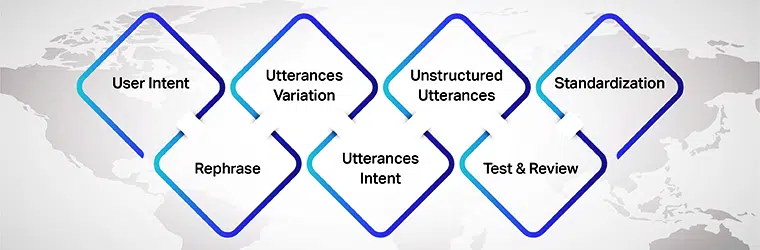
用户意图
最重要的是,在为您的 AI 模型准备话语时,请确保您了解您正在为其开发数据集的用户意图。 您需要弄清楚用户在与 AI 模型交谈时可能输入的不同话语。
话语的变化
变化是此过程的重要组成部分,因为每个意图的变化越多,您将获得更好的结果。 因此,请确保创建用户话语的多种变体。 你可以这样做
- 为相同的句子创建短句、中句和大句。
- 改变句子的单词和长度。
- 使用独特的词。
- 将句子复数。
- 混淆语法。



